[행정학] 조직변화의 성공사례 모음집 - 조직혁신
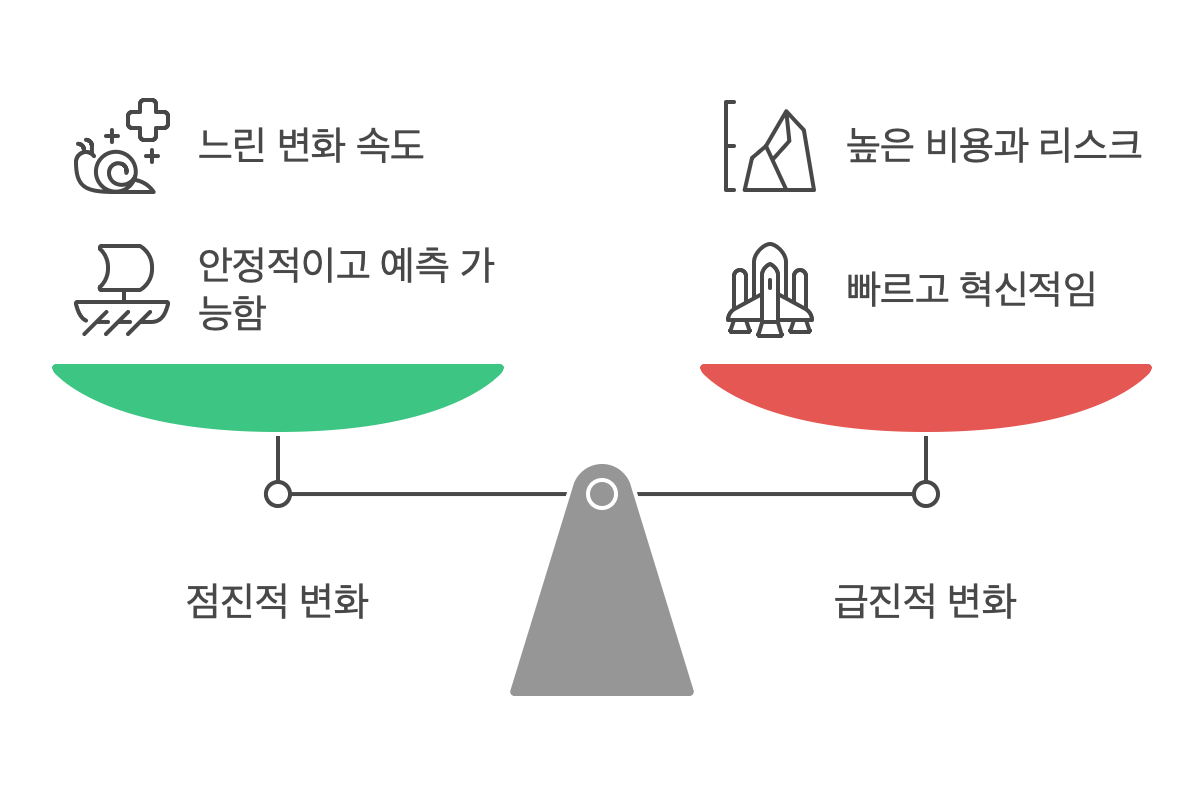
목차 도요타의 카이젠(Kaizen) 시스템: 점진적 변화의 성공사례카이젠 시스템의 특징:전 직원의 자발적 참여: 모든 직원이 지속적으로 개선 방법을 고민하고 제안작은 개선의 누적: 사소한 개선점을 찾아 효율성 향상높은 제안 채택률: 연간 직원 1인당 평균 11건의 제안, 90% 채택카이젠 시스템의 성과:원가 절감생산 효율성 향상고품질 유지도요타는 이를 통해 글로벌 자동차 시장에서 강력한 경쟁력을 확보했습니다.주의점:최근 과도한 원가 절감으로 인한 품질 문제가 발생하여, 점진적 변화의 한계점도 드러났습니다. 따라서 점진적 변화를 추구할 때는 장기적인 관점에서 균형을 유지하는 것이 중요합니다. 넷플릭스의 급진적 조직변화 성공사례주요 변화 내용:무제한 휴가 정책직원들에게 무제한 휴가 제공전통적인 휴가 정책에..