분석 과제 우선순위 평가기준과 우선순위 선정 방법 - 빅데이터 분석
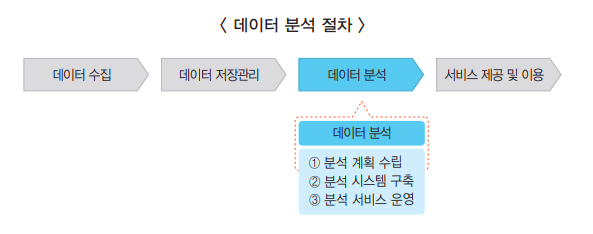
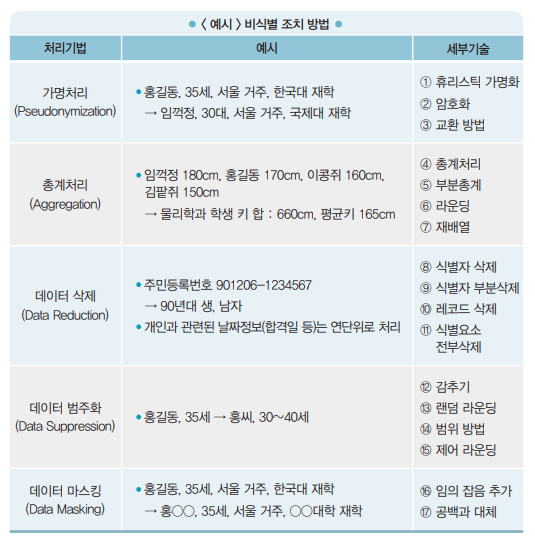
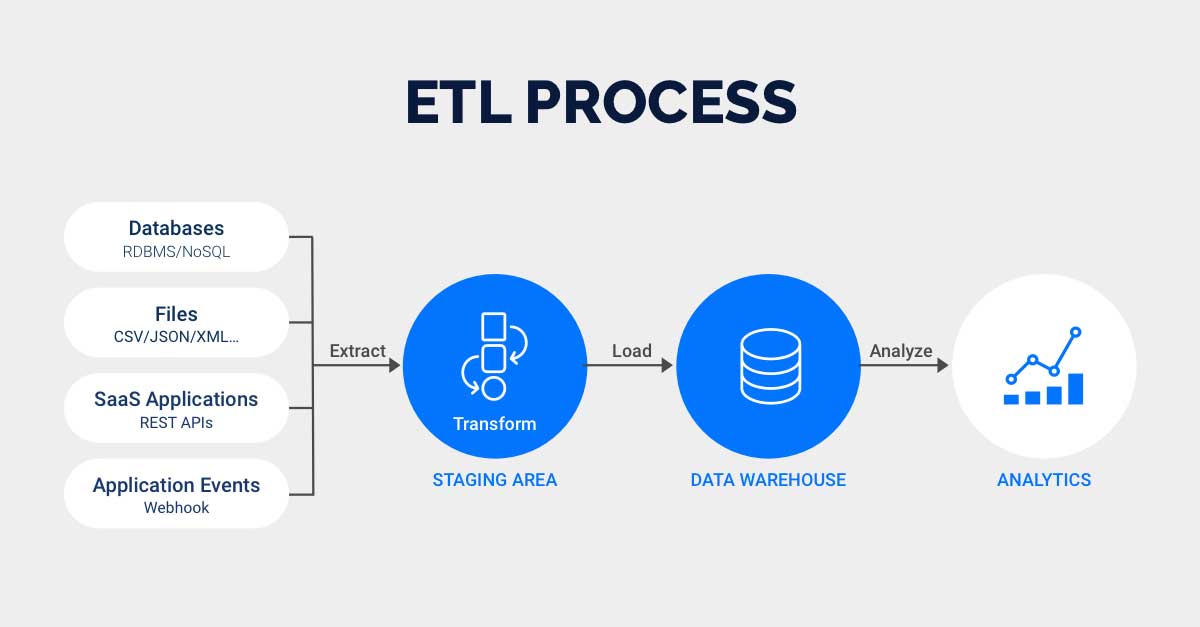
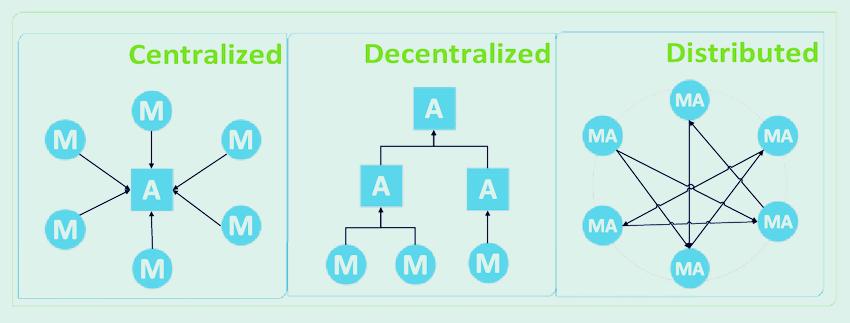
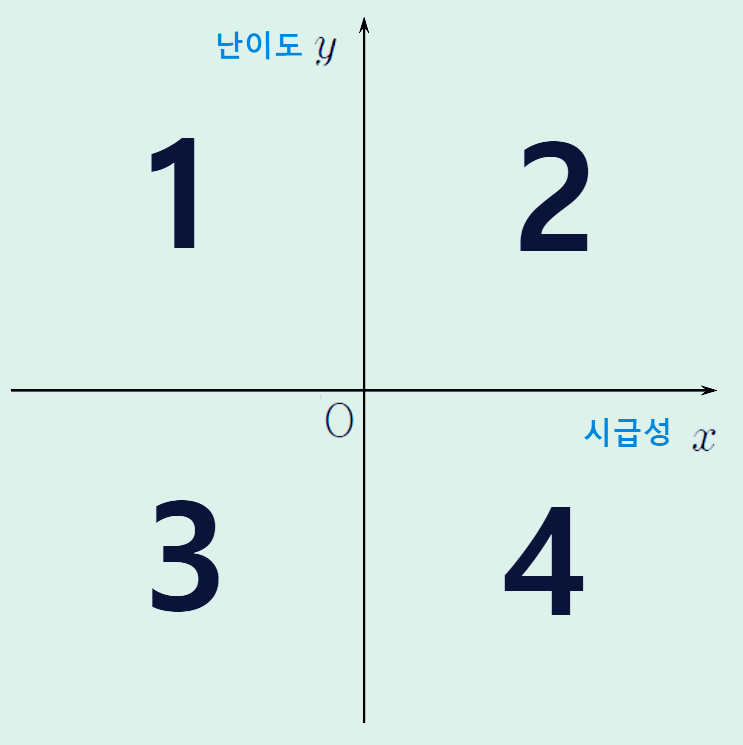
목차 빅데이터 분석 과제 우선순위 평가 기준 평가관점 평가요소 시급성 전략적 중요도 목표가치 난이도 데이터 획득 비용 데이터 가공 비용 데이터 저장 비용 분석 적용 비용 분석 수준 분석 ROI 요소 roi 요소 특징 내용 투자비용 요소 데이터 크기 데이터 규모와 양 데이터 형태 데이터 종류와 유형 데이터 속도 데이터 생성과 처리 속도 비즈니스 효과 가치 분석 결과 활용 및 비즈니스 실행을 통한 획득 가치 우선순위 선정 방법 난이도와 시급성을 기준으로 분석 과제 유형을 분류한다. 우선순위 기준을 시급성에 둘 경우 순서 : 3 > 4 > 1 > 2 우선순위 기준을 난이도에 둘 경우 순서 : 3 > 1 > 4 > 2 관련 글 아래의 빅데이터 분석기사 카테고리에서, 빅데이터에 관한 글 또는 분석기사 준비를 위한..