반응형
목차
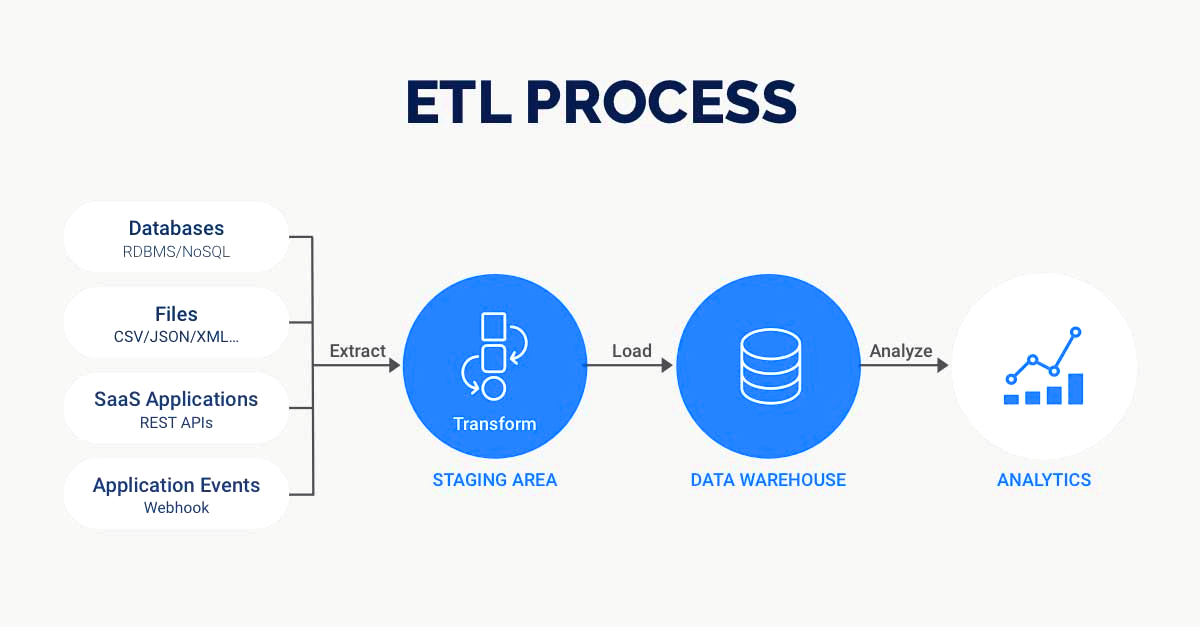
빅데이터 처리과정
| 생성 | 빅 데이터는 소셜 미디어, IoT 장치, 트랜잭션 시스템 등과 같은 다양한 소스에서 생성됩니다. |
| 수집 | 데이터가 생성되면 추가 처리를 위해 데이터를 수집하고 중앙 위치로 전송해야 합니다. |
| 저장 | 데이터가 수집된 후 추가 처리를 위해 중앙 위치에 저장해야 합니다. 이는 데이터 웨어하우스, 데이터 레이크 및 NoSQL 데이터베이스와 같은 다양한 스토리지 솔루션을 사용하여 수행할 수 있습니다. |
| 처리 | 데이터가 저장되면 분석에 사용할 수 있도록 정리, 변환 및 정규화해야 합니다. |
| 분석 | 데이터가 처리된 후 기술 통계, 데이터 시각화, 기계 학습과 같은 다양한 도구와 기술을 사용하여 분석할 수 있습니다. |
| 시각화 | 빅데이터 처리 기술의 마지막 단계는 데이터 시각화로, 데이터에서 얻은 통찰력과 결과를 그래프, 차트, 표와 같은 이해하기 쉬운 형식으로 제시하는 데 사용됩니다. |
빅데이터 수집 방법
| 데이터 레이크 | 빅 데이터를 저장하는 새로운 방법인 데이터 레이크는 대량의 정형 데이터와 비정형 데이터를 모두 처리하도록 설계되었습니다. |
| NoSQL | 이러한 유형의 데이터베이스는 대량의 비정형 데이터를 처리하고 처리를 위해 데이터에 빠르게 액세스할 수 있도록 설계되었습니다. |
| 크롤링 | 이 방법은 소프트웨어 도구를 사용하여 웹 사이트 및 기타 온라인 소스에서 자동으로 데이터를 추출하고 나중에 분석하기 위해 저장합니다. |
| 로그 수집기 | 이 방법은 나중에 분석하고 저장하기 위해 로그 파일에 데이터를 기록하는 것과 관련됩니다. |
| 센서 네트워크 | 이 방법에는 IoT 장치 및 기타 연결된 장치에서 데이터를 수집하고 저장하는 작업이 포함됩니다. |
| API | 애플리케이션 프로그래밍 인터페이스는 Google, Facebook, Twitter 등과 같은 다양한 웹 기반 플랫폼에서 데이터를 수집하고 나중에 분석하기 위해 저장할 수 있도록 합니다. |
| ETL | 이 방법에는 다양한 소스에서 데이터를 추출하고, 분석에 사용할 수 있도록 변환하고, 저장을 위해 중앙 위치에 로드하는 작업이 포함됩니다. |
빅데이터 저장 방법
- NoSQL 데이터베이스: NoSQL 데이터베이스는 대량의 비정형 데이터를 처리하고 처리를 위해 데이터에 빠르게 액세스할 수 있도록 설계되었습니다. 고정된 스키마를 사용하지 않고 데이터 쿼리를 위해 SQL에 의존하지 않는다는 점에서 기존의 관계형 데이터베이스와 다릅니다. NoSQL 데이터베이스의 예로는 MongoDB, Cassandra 및 Hbase가 있습니다.
- 공유 데이터 시스템: 공유 데이터 시스템은 여러 사용자 또는 시스템이 동일한 데이터에 동시에 액세스할 수 있는 저장 방법입니다. 이는 공유 파일 시스템 또는 공유 데이터베이스를 통해 수행할 수 있습니다.
- 병렬 데이터베이스 관리 시스템: 병렬 데이터베이스 관리 시스템은 데이터 및 작업 부하를 여러 서버 또는 시스템에 분산하여 대량의 데이터를 처리하도록 설계된 일종의 데이터베이스 관리 시스템입니다. 이를 통해 데이터에 빠르게 액세스하고 확장성을 높일 수 있습니다.
- 분산 파일 시스템: 분산 파일 시스템은 파일이 여러 서버 또는 시스템에 저장되는 저장 방법입니다. 이를 통해 확장성과 내결함성이 향상되고 데이터에 더 빠르게 액세스할 수 있습니다. 분산 파일 시스템의 예로는 HDFS(Hadoop 분산 파일 시스템) 및 GlusterFS가 있습니다.
- NAS(Network Attached Storage): 이것은 여러 사용자 또는 시스템이 네트워크를 통해 파일에 액세스하고 파일을 공유할 수 있도록 하는 스토리지 시스템 유형입니다. NAS 장치는 파일 기반 데이터 스토리지 서비스만 제공하는 네트워크에 연결된 전문화된 독립 컴퓨터입니다.
빅데이터 처리 방법
- 빅 데이터 처리 방법: 일괄 처리, 실시간 처리 및 스트리밍 처리를 포함하여 빅 데이터를 처리하는 데 사용되는 여러 가지 방법이 있습니다. 일괄 처리는 일반적으로 하룻밤 사이에 예약된 방식으로 대량의 데이터를 처리하는 데 사용됩니다. 실시간 처리는 거의 실시간으로 생성되는 데이터를 처리하는 데 사용됩니다. 스트리밍 처리는 일반적으로 IoT 장치 및 기타 연결된 장치에서 생성되는 데이터를 실시간으로 처리하는 데 사용됩니다.
- 분산 시스템: 분산 시스템은 여러 컴퓨터 또는 시스템에 분산되어 각 시스템이 데이터 및 워크로드의 일부를 처리하는 시스템입니다. 이를 통해 확장성과 내결함성이 향상되고 데이터에 더 빠르게 액세스할 수 있습니다. 분산 시스템은 HDFS(Hadoop Distributed File System) 또는 GlusterFS와 같은 분산 파일 시스템에서 대량의 데이터를 저장하고 처리하는 데 자주 사용됩니다.
- 병렬 시스템: 병렬 시스템은 데이터와 워크로드를 단일 머신 내의 여러 프로세서 또는 코어로 나누어 대량의 데이터를 처리하도록 설계된 시스템입니다. 이를 통해 데이터 처리 속도가 빨라지고 성능이 향상됩니다. 병렬 시스템은 병렬 데이터베이스, 병렬 컴퓨팅 및 병렬 데이터 처리 프레임워크에서 자주 사용됩니다.
- 분산 병렬 시스템: 이름에서 알 수 있듯이 데이터가 분산 파일 시스템에 저장되고 처리가 여러 시스템에서 병렬로 수행되는 분산 및 병렬 시스템의 조합입니다.
- Hadoop: Hadoop은 대량의 데이터를 처리하도록 설계된 오픈 소스 분산 처리 프레임워크입니다. 여기에는 대량의 데이터를 저장하기 위한 HDFS(Hadoop Distributed File System)와 여러 시스템에서 병렬로 데이터를 처리하기 위한 MapReduce 프로그래밍 모델이 포함됩니다.
- Apache Spark: Apache Spark는 대량의 데이터를 처리하도록 설계된 오픈 소스 분산 처리 프레임워크입니다. Hadoop의 MapReduce에 대한 대안이며 더 빠르고 유연하게 설계되었습니다. 더 빠른 데이터 처리를 위한 메모리 내 컴퓨팅 엔진과 Python, Java 및 Scala 프로그래밍을 위한 고급 API를 제공합니다.
- MapReduce: MapReduce는 여러 시스템에서 병렬로 빅 데이터를 처리하기 위한 프로그래밍 모델입니다. 데이터를 병렬로 처리하는 데 사용되는 "map" 기능과 "reduce" 기능의 두 가지 주요 기능을 기반으로 합니다. MapReduce는 Hadoop 및 Apache Spark를 비롯한 많은 빅 데이터 처리 프레임워크의 기반입니다.
빅데이터 분석
빅데이터 분석 방법 분류
| 탐구 요인 분석 EFA | EFA는 대규모 데이터 세트에서 패턴과 구조를 식별하는 데 사용되는 통계적 방법입니다. EFA의 목표는 많은 변수 간의 관계를 설명할 수 있는 일련의 요인을 식별하는 것입니다. 일반적으로 사회 과학, 심리학 및 시장 조사에서 데이터 세트의 기본 차원 또는 요소를 식별하는 데 사용됩니다. |
| 확인 요인 분석 CFA | CFA는 데이터 세트에서 요인의 수와 변수 간의 관계 구조를 확인하는 데 사용되는 통계적 방법입니다. 모델이 선험적으로 지정된 변수 집합의 측정 모델을 테스트하는 데 사용됩니다. EFA를 사용하여 식별된 데이터 세트의 요인 구조를 확인하기 위해 사회 과학, 심리학 및 시장 조사에서 일반적으로 사용됩니다. |
빅데이터 분석 방법 종류
- 분류: 분류는 통계 알고리즘을 사용하여 주어진 입력에 레이블 또는 범주를 할당하는 것과 관련된 빅 데이터 분석 방법입니다. 일련의 입력 기능을 기반으로 관찰의 클래스 또는 범주를 예측하는 데 사용됩니다. 분류에 일반적으로 사용되는 알고리즘에는 결정 트리, 랜덤 포레스트, 나이브 베이즈 및 지원 벡터 머신이 포함됩니다.
- 클러스터링: 클러스터링은 유사한 데이터 포인트를 특성에 따라 그룹화하는 빅 데이터 분석 방법입니다. 대규모 데이터 세트에서 패턴과 구조를 식별하는 데 사용됩니다. 클러스터링에 일반적으로 사용되는 알고리즘에는 K-평균, 계층적 클러스터링 및 DBSCAN이 포함됩니다.
- 기계 학습: 기계 학습은 알고리즘을 사용하여 데이터에서 패턴과 통찰력을 찾는 빅 데이터 분석 방법입니다. 예측을 하고, 데이터를 분류하고, 패턴을 식별하는 데 사용됩니다. 기계 학습에 일반적으로 사용되는 알고리즘에는 Neural Networks, Random Forest 및 Gradient Boosting이 있습니다.
- 텍스트 마이닝: 텍스트 마이닝은 자연어 처리 기술을 사용하여 텍스트 데이터에서 인사이트를 추출하는 빅데이터 분석 방법입니다. 소셜 미디어 게시물, 고객 리뷰 및 뉴스 기사와 같은 대규모 텍스트 데이터 세트에서 패턴과 추세를 식별하는 데 사용됩니다.
- 웹 마이닝: 웹 마이닝은 웹 사이트 및 기타 온라인 소스에서 정보를 추출하는 기술을 사용하는 빅 데이터 분석 방법입니다. 클릭 스트림 데이터, 검색 쿼리 및 소셜 미디어 게시물과 같은 대규모 웹 데이터 세트에서 패턴과 추세를 식별하는 데 사용됩니다.
- 오피니언 마이닝: 오피니언 마이닝은 자연어 처리 기술을 사용하여 텍스트 데이터에서 인사이트를 추출하여 작성자의 태도, 의견 및 감정을 식별하는 빅데이터 분석 방법입니다.
- 현실 마이닝: 현실 마이닝은 모바일 장치, 소셜 미디어 및 기타 소스의 데이터를 사용하여 물리적 세계에서 인간의 행동을 연구하는 빅 데이터 분석 방법입니다. 센서 및 기타 IoT 장치에서 수집된 데이터의 패턴 및 추세를 식별하는 데 사용됩니다.
- 소셜 네트워크 분석: 소셜 네트워크 분석은 Facebook, Twitter 및 LinkedIn과 같은 소셜 네트워크에서 인사이트를 추출하는 기술을 사용하는 빅 데이터 분석 방법입니다. 개인과 그룹 간의 관계와 같은 대규모 소셜 네트워크 데이터 세트의 패턴과 추세를 식별하는 데 사용됩니다.
- 감성 분석: 의견 마이닝이라고도 하는 감정 분석은 컴퓨터 기술을 사용하여 텍스트 데이터에서 주관적인 정보를 식별하고 추출하는 자연어 처리의 하위 분야입니다. 정서 분석의 목표는 특정 주제, 제품 또는 엔터티에 대한 작성자의 태도, 감정 또는 의견을 결정하는 것입니다. 감정 분석은 텍스트를 긍정, 부정 또는 중립으로 분류하거나 -1과 1 사이의 점수와 같은 척도의 숫자 값으로 감정의 정도를 정량화하는 데 사용할 수 있습니다.
다음 글
정보의 호텔에는 미래의 데이터 전문가가 되실 분들을 위해 빅데이터분석, 데이터분석에 관한 글을 아래의 페이지에 정리해 놓았습니다.
'자격증/빅데이터분석기사' 카테고리의 글 목록
모든 분야의 정보를 담고 있는 정보의 호텔입니다.
jkcb.tistory.com
위 페이지는 빅데이터분석기사 / 데이터분석전문가 / 데이터분석준전문가 모두 유용하게 사용하실 수 있습니다.
반응형