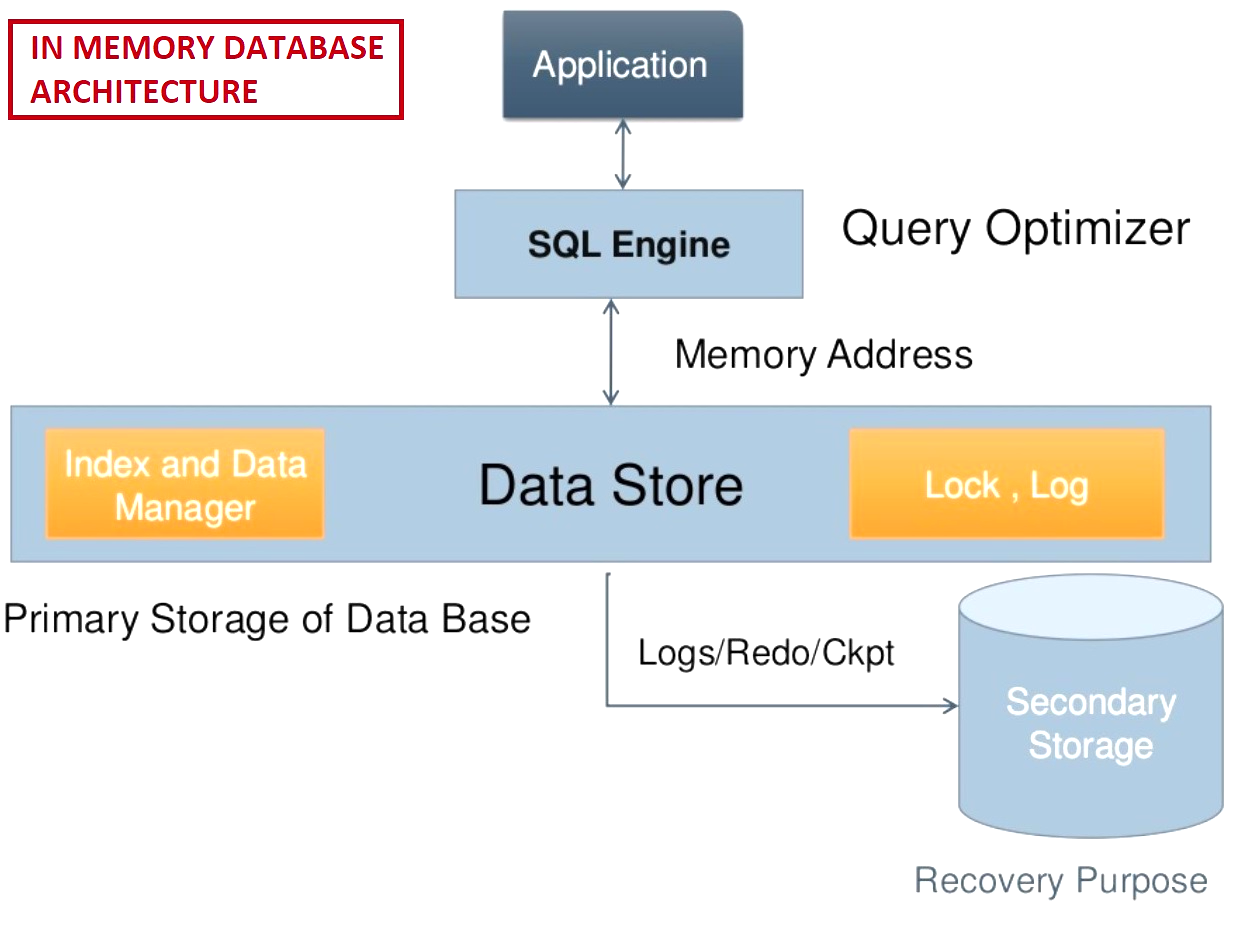
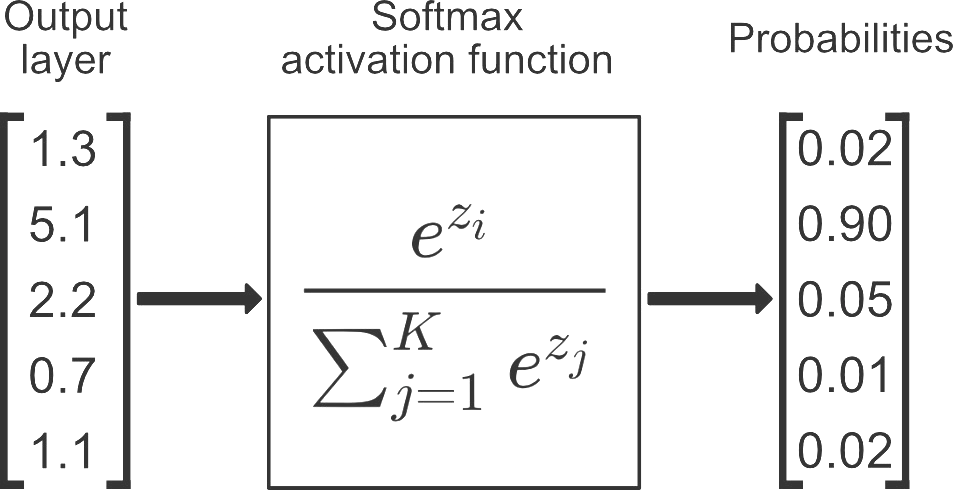
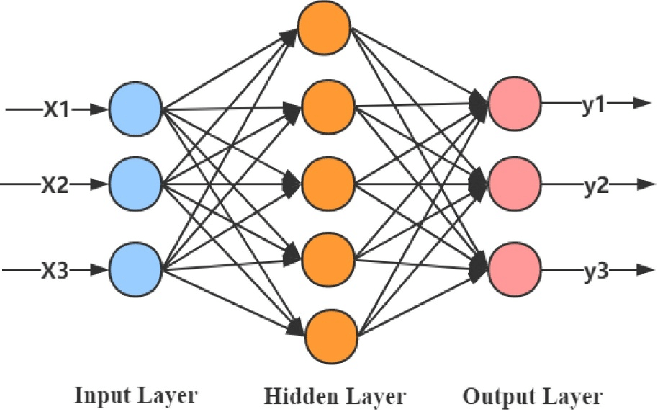
[소프트웨어] 펌웨어란 무엇인가? 펌웨어 특징,종류,예시
목차 펌웨어 뜻 펌웨어는 컴퓨터, 스마트폰 또는 라우터와 같은 장치에 미리 설치되어 장치가 제대로 작동하는 데 필요한 지침을 제공하는 소프트웨어의 한 유형입니다. ROM(Read-Only Memory)에 저장되며 일반적으로 사용자가 수정하지 않습니다. 펌웨어는 설치된 장치에 따라 다르며 장치의 하드웨어 구성요소에 대한 낮은 수준의 제어를 제공합니다. 여기에는 장치의 입력/출력 인터페이스 제어, 전원 관리 및 다른 장치와의 통신 조정과 같은 기능이 포함될 수 있습니다. 펌웨어의 특징 장치의 특정 하드웨어를 제어하도록 설계되었습니다: 펌웨어는 마이크로프로세서, 메모리 및 입출력 인터페이스와 같은 장치의 하드웨어 구성 요소와 직접 상호 작용하도록 설계되었습니다. 읽기 전용 메모리에 저장됩니다. 펌웨어는 일반적..