인공 신경망 분야에서 데이터는 모델을 훈련하고 평가하는 데 중요한 구성 요소입니다. 훈련 데이터와 시험 데이터의 두 가지 유형의 데이터가 일반적으로 사용됩니다. 이 글에서는 신경망 학습의 훈련 데이터와 시험 데이터에 대해서 설명합니다.
목차
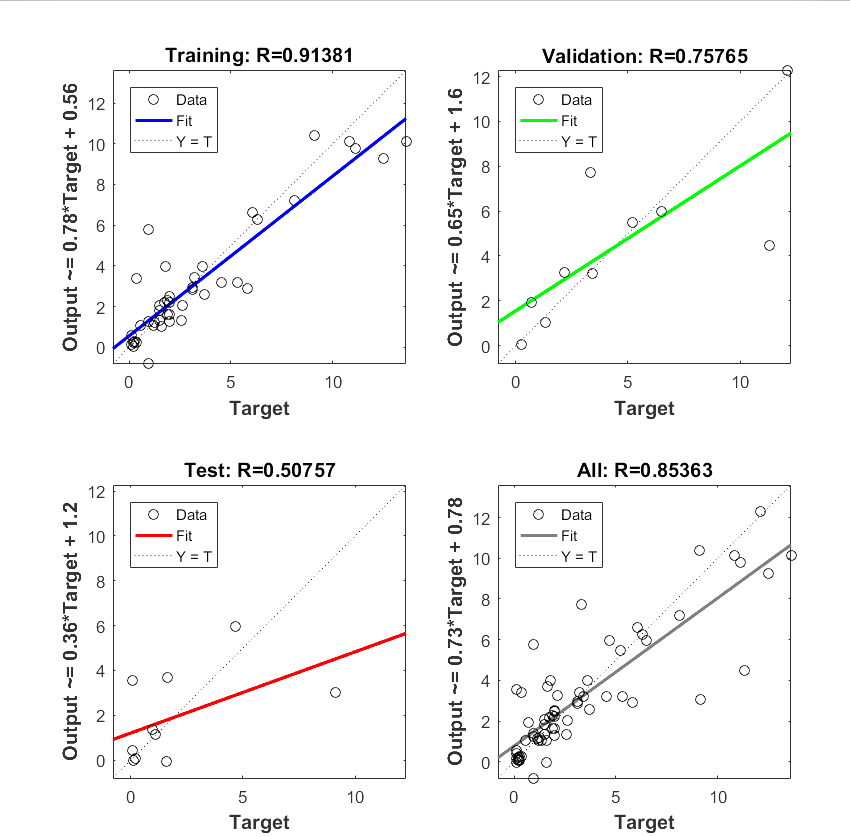
훈련데이터와 시험데이터의 특징
훈련 데이터는 모델을 교육하는 데 사용됩니다. 모델이 입력과 출력 간의 관계를 학습하는 데 사용하는 입력-출력 쌍 세트로 구성됩니다. 모델은 훈련 데이터의 예측과 실제 출력 간의 차이를 최소화하기 위해 내부 매개변수를 조정하여 훈련됩니다.
반면 시험 데이터는 훈련된 모델의 성능을 평가하는 데 사용됩니다. 훈련 중에 모델이 보지 못한 별도의 입력-출력 쌍 세트로 구성됩니다. 테스트 데이터에 대한 모델의 예측은 성능을 측정하기 위해 실제 출력과 비교됩니다.
시험 데이터는 모델이 해결하려는 문제를 대표해야 하며 가능한 입력과 출력을 광범위하게 포함할 수 있도록 신중하게 선택해야 합니다. 검증 세트라고 하는 테스트용으로 다른 데이터 세트를 사용하는 것도 모델의 일반화 가능성을 보장하는 좋은 방법입니다.
모델을 훈련시키기 위해 충분한 양의 데이터를 사용하는 것뿐만 아니라 보이지 않는 예까지 모델이 잘 일반화될 수 있도록 다양한 데이터를 사용하는 것도 중요합니다. 이는 데이터 확대 및 정규화와 같은 기술을 사용하여 달성할 수 있습니다.
요약하면 훈련 데이터는 모델을 훈련하는 데 사용되고 테스트 데이터는 성능을 평가하는 데 사용됩니다. 둘 다 강력하고 정확한 모델을 구축하는 데 중요합니다. 교육과 테스트 모두 대표적이고 다양한 데이터 세트를 사용하고 교육을 위해 충분한 양의 데이터를 사용하는 것이 중요합니다.
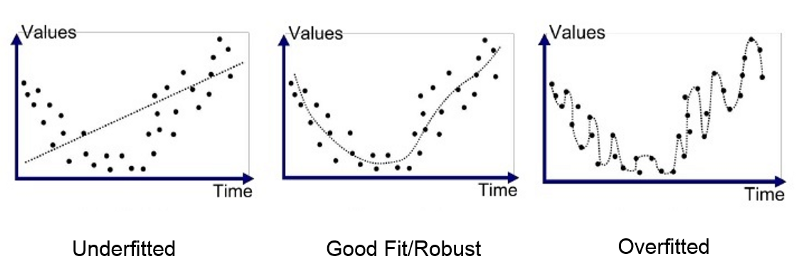
과적합 (오버피팅)
인공 신경망 분야에서 과적합은 훈련 데이터에 대해 모델이 너무 잘 훈련되었을 때 발생하는 일반적인 문제입니다. 모델이 기본 패턴 대신 훈련 데이터에서 노이즈를 학습했을 때 발생합니다.
모델이 훈련되면 훈련 데이터의 입력과 출력 간의 관계를 학습합니다. 그러나 모델에 너무 많은 매개 변수가 있으면 관계뿐만 아니라 훈련 데이터의 노이즈도 학습할 수 있습니다. 이는 훈련 데이터에서는 잘 수행되지만 보이지 않는 데이터에서는 제대로 수행되지 않음을 의미합니다.
학습 데이터와 테스트 데이터에 대한 모델의 성능을 비교하여 과적합을 식별할 수 있습니다. 모델이 훈련 데이터에서는 잘 수행되지만 테스트 데이터에서는 제대로 수행되지 않으면 과적합일 가능성이 높습니다.
과적합을 방지하는 한 가지 방법은 정규화와 같은 기술을 사용하는 것입니다. 정규화는 모델의 손실 함수에 페널티 항을 추가하는 방법입니다. 이 용어는 모델이 큰 가중치를 갖지 않도록 하여 과적합을 줄일 수 있습니다. 다른 기술로는 Dropout 사용, 조기 중지 및 더 작은 모델 사용이 있습니다.
과적합을 방지하는 또 다른 방법은 교육에 더 많은 데이터를 사용하는 것입니다. 더 많은 데이터가 있는 모델은 기본 패턴을 더 잘 학습할 수 있으므로 과대적합될 가능성이 적습니다.
요약하면 과적합은 모델이 훈련 데이터에 대해 너무 잘 훈련되어 기본 패턴 대신 잡음을 학습했을 때 발생하는 문제입니다. 학습 데이터와 테스트 데이터에 대한 모델의 성능을 비교하여 식별할 수 있습니다. 과적합을 방지하기 위해 정규화, 드롭아웃, 조기 중단, 더 작은 모델 또는 더 많은 데이터 사용과 같은 기술을 사용할 수 있습니다.
관련 글
'컴퓨터과학/딥러닝' 카테고리의 글 목록
모든 분야의 정보를 담고 있는 정보의 호텔입니다. 주로 컴전기입니다.
jkcb.tistory.com