오차 역전파는인공 신경망 훈련에 널리 사용되는 알고리즘으로, 주어진 작업에 대한 성능을 향상시키기 위해 네트워크의 가중치를 조정하는 데 사용할 수 있는 지도 학습 알고리즘입니다. 이 글에서는 오차 역전파의 특징과, 오차역전파법을 이용해 신경망을 구현하는 방법에 대해서 설명하고 있습니다.
목차
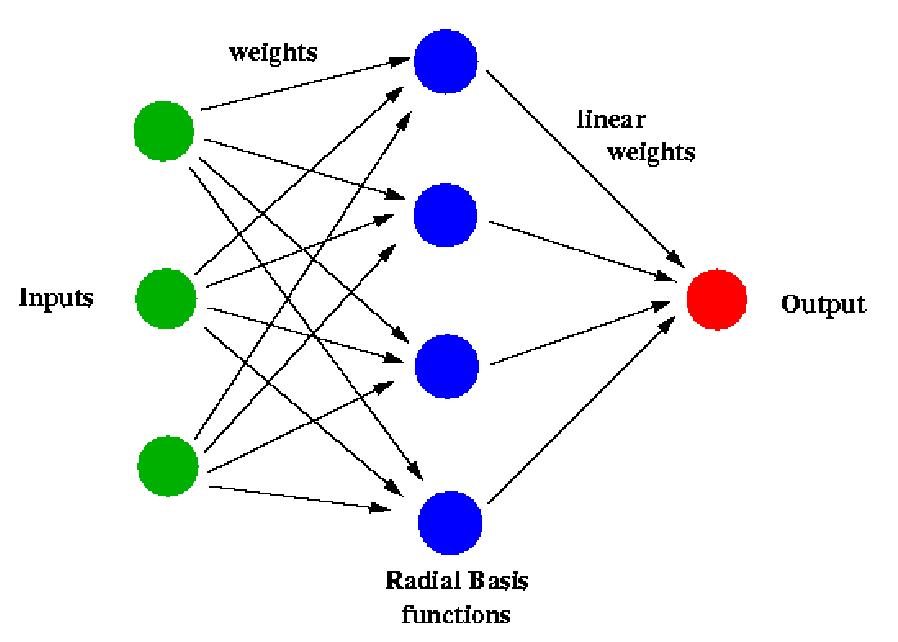
오차역전파법 이란
오차 역전파의 기본 아이디어는 주어진 입력에 대해 네트워크의 출력과 원하는 출력 사이의 오차를 계산한 다음 이 오차를 줄이기 위해 네트워크의 가중치를 조정하는 것입니다. 오차는 네트워크의 출력과 원하는 출력 간의 차이를 측정하는 비용 함수를 사용하여 계산됩니다.
오차 역전파 과정은 입력이 네트워크를 통과하고 출력이 생성되는 네트워크를 통한 정방향 통과로 시작됩니다. 그런 다음 오류는 비용 함수를 사용하여 계산됩니다. 다음으로 오류는 네트워크를 통해 역전파되며 여기에는 네트워크의 각 가중치에 대한 오류의 기울기 계산이 포함됩니다.
[컴퓨터과학/딥러닝] - 딥러닝에서 역전파란 무엇인가? 인공신경망 훈련 역전파 학습
오차의 기울기는 오류를 줄이기 위해 네트워크의 가중치를 업데이트하는 데 사용됩니다. 이것은 일반적으로 확률적 경사하강법과 같은 최적화 알고리즘을 사용하여 수행됩니다. 오류가 최소화될 때까지 프로세스가 반복되고 네트워크가 훈련된 것으로 간주됩니다.
[컴퓨터과학/딥러닝] - 딥러닝에서 미분이란? 인공신경망의 편도함수와 미분의 특징
오류 역전파의 주요 이점 중 하나는 피드포워드 네트워크, 순환 네트워크 및 컨볼루션 네트워크를 비롯한 다양한 신경망 아키텍처를 훈련하는 데 사용할 수 있다는 것입니다. 또한 구현하기가 상대적으로 쉬워 많은 연구자와 실무자에게 인기 있는 선택입니다.
요약하면 오류 역전파는 인공 신경망 훈련을 위한 강력한 알고리즘입니다. 네트워크를 통해 입력을 전달하고, 오류를 계산하고, 네트워크를 통해 오류를 역전파하고, 오류를 줄이기 위해 가중치를 업데이트하는 작업이 포함됩니다. 다양한 신경망 아키텍처를 훈련하는 데 사용할 수 있으며 비교적 구현하기 쉽습니다.
오차역전파법 신경망 구현
import numpy as np
class NeuralNetwork:
def __init__(self, layers, learning_rate):
self.layers = layers
self.learning_rate = learning_rate
self.weights = []
for i in range(1, len(layers) - 1):
self.weights.append(np.random.randn(layers[i-1] + 1, layers[i] + 1))
self.weights.append(np.random.randn(layers[i] + 1, layers[i+1]))
def sigmoid(self, x):
return 1.0 / (1.0 + np.exp(-x))
def sigmoid_derivative(self, x):
return x * (1.0 - x)
def fit(self, X, y, epochs):
X = np.c_[X, np.ones((X.shape[0]))]
for k in range(epochs):
i = np.random.randint(X.shape[0])
a = [X[i]]
for l in range(len(self.weights)):
a.append(self.sigmoid(np.dot(a[l], self.weights[l])))
error = y[i] - a[-1]
deltas = [error * self.sigmoid_derivative(a[-1])]
for l in range(len(a) - 2, 0, -1):
deltas.append(deltas[-1].dot(self.weights[l].T)*self.sigmoid_derivative(a[l]))
deltas.reverse()
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += self.learning_rate * layer.T.dot(delta)
def predict(self, x):
x = np.c_[x, np.ones((x.shape[0]))]
for l in range(0, len(self.weights)):
x = self.sigmoid(np.dot(x, self.weights[l]))
return x오차역전파법 기울기 검증 구현
import numpy as np
class NeuralNetwork:
def __init__(self, layers, learning_rate):
self.layers = layers
self.learning_rate = learning_rate
self.weights = []
for i in range(1, len(layers) - 1):
self.weights.append(np.random.randn(layers[i-1] + 1, layers[i] + 1))
self.weights.append(np.random.randn(layers[i] + 1, layers[i+1]))
def sigmoid(self, x):
return 1.0 / (1.0 + np.exp(-x))
def sigmoid_derivative(self, x):
return x * (1.0 - x)
def fit(self, X, y, epochs, epsilon=1e-5):
X = np.c_[X, np.ones((X.shape[0]))]
for k in range(epochs):
i = np.random.randint(X.shape[0])
a = [X[i]]
for l in range(len(self.weights)):
a.append(self.sigmoid(np.dot(a[l], self.weights[l])))
error = y[i] - a[-1]
deltas = [error * self.sigmoid_derivative(a[-1])]
for l in range(len(a) - 2, 0, -1):
deltas.append(deltas[-1].dot(self.weights[l].T)*self.sigmoid_derivative(a[l]))
deltas.reverse()
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += self.learning_rate * layer.T.dot(delta)
self.gradient_check(X[i], y[i], self.weights[i], epsilon)
def gradient_check(self, x, y, weight, epsilon):
"""
Gradient check to ensure the backpropagation is implemented correctly
"""
#calculate the cost function with weights
cost = self.cost_function(x, y, weight)
#calculate the weight gradient using backpropagation
weight_gradient = self.weight_gradient(x, y, weight)
#create a copy of the weight
weight_shape = weight.shape
weight_copy = weight.copy()
#iterate over the weight and calculate the numerical gradient for each weight
for i in range(weight_shape[0]):
for j in range(weight_shape[1]):
weight_copy[i][j] += epsilon
cost_plus = self.cost_function(x, y, weight_copy)
weight_copy[i][j] -= 2*epsilon
cost_minus = self.cost_function(x, y, weight_copy)
#calculate the numerical gradient
numerical_gradient = (cost_plus - cost_minus) / (2*epsilon)
#check the difference between the backpropagation gradient and numerical gradient
weight_copy[i][j] += epsilon
gradient_diff = abs(numerical_gradient - weight_gradient[i][j])
if gradient_diff > epsilon:
print("Gradient Check Error: weight({},{}), numerical_gradient = {}, weight_gradient = {}".format(i, j, numerical_gradient, weight_gradient[i][j]))
def cost_function(self, x, y, weight):
"""
Calculate the cost function
"""
prediction = self.predict(x, weight)
cost = np.mean((prediction - y)**2)
return cost
def weight_gradient(self, x, y, weight):
"""
Calculate the weight gradient using backpropagation
"""
a = [np.append(x, 1)]
for l in range(len(weight)):
a.append(self.sigmoid(np.dot(a[l], weight[l])))
error = y - a[-1]
deltas = [error * self.sigmoid_derivative(a[-1])]
for l in range(len(a) - 2, 0, -1):
deltas.append(deltas[-1].dot(weight[l].T)*self.sigmoid_derivative(a[l]))
weight_gradient = np.atleast_2d(a[0]).T.dot(np.atleast_2d(deltas[0]))
return weight_gradient
def predict(self, x, weight):
"""
Make predictions using the trained model
"""
x = np.append(x, 1)
for l in range(0, len(weight)):
x = self.sigmoid(np.dot(x, weight[l]))
return x오차역전파법 학습 구현
import numpy as np
class NeuralNetwork:
def __init__(self, layers, learning_rate):
self.layers = layers
self.learning_rate = learning_rate
self.weights = []
for i in range(1, len(layers) - 1):
self.weights.append(np.random.randn(layers[i-1], layers[i]))
self.weights.append(np.random.randn(layers[i], layers[i+1]))
def sigmoid(self, x):
return 1.0 / (1.0 + np.exp(-x))
def sigmoid_derivative(self, x):
return x * (1.0 - x)
def train(self, X, y, epochs):
for i in range(epochs):
# Forward pass
activations = [X]
for weight in self.weights:
a = np.dot(activations[-1], weight)
z = self.sigmoid(a)
activations.append(z)
# Backward pass
error = y - activations[-1]
delta = error * self.sigmoid_derivative(activations[-1])
for i in range(len(self.weights), 0, -1):
gradient = np.dot(activations[i-1].T, delta)
self.weights[i-1] += self.learning_rate * gradient
delta = np.dot(delta, self.weights[i-1].T) * self.sigmoid_derivative(activations[i-1])
def predict(self, x):
a = np.dot(x, self.weights[0])
z = self.sigmoid(a)
for i in range(1, len(self.weights)):
a = np.dot(z, self.weights[i])
z = self.sigmoid(a)
return z더보기
'컴퓨터과학/딥러닝' 카테고리의 글 목록
모든 분야의 정보를 담고 있는 정보의 호텔입니다. 주로 컴전기입니다.
jkcb.tistory.com