반응형
목차
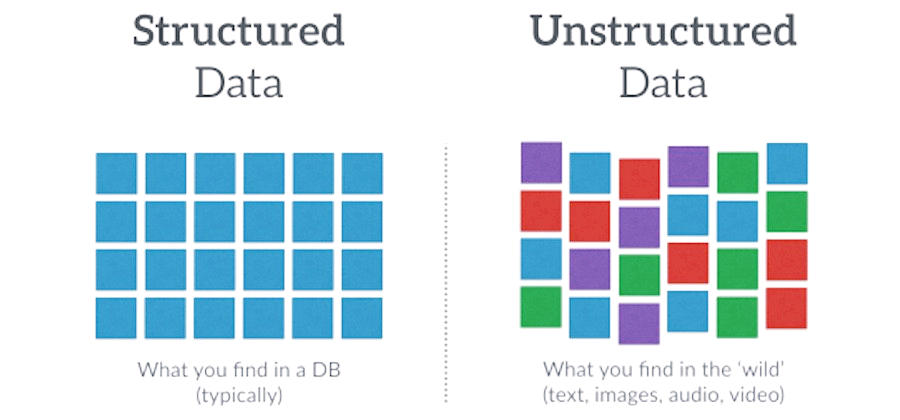
데이터의 정의
데이터는 통찰력, 지식 및 정보를 추출하기 위해 수집, 저장 및 처리되는 원시 정보를 의미합니다. 숫자, 텍스트, 이미지, 오디오 및 기타 형태의 디지털 및 아날로그 정보의 형태일 수 있습니다. 데이터는 스프레드시트와 같이 구조화되거나 텍스트 문서와 같이 구조화되지 않을 수 있습니다. 정보는 수집되는 맥락과 목적에 따라 질적이거나 양적이거나 수치적이거나 범주적일 수 있습니다. 데이터는 의사 결정, 과학적 연구 및 많은 기술 발전을 위한 기반이며 AI, 기계 학습 및 세상을 변화시키는 기타 기술의 원동력입니다.
데이터의 특징
- 데이터는 정성적(텍스트, 이미지) 또는 정량적(숫자, 통계)일 수 있습니다.
- 구조적(특정 형식으로 구성됨) 또는 비구조적(특정 형식으로 구성되지 않음)일 수 있습니다.
- 데이터는 연속적(모든 값을 가질 수 있음) 또는 불연속적(제한된 값 집합)일 수도 있습니다.
- 데이터는 기본 데이터(연구원이 수집한 데이터) 또는 보조 데이터(이미 존재하는 데이터)일 수도 있습니다.
데이터의 구분
| 정량적 데이터 | 양적 데이터는 측정하고 비교할 수 있는 수치 데이터입니다.통계 및 연구 조사에 자주 사용됩니다. 예를 들면 연령, 소득 수준, 시험 점수 등이 있습니다. |
| 정성적 데이터 | 정성적 데이터는 특성이나 속성을 설명하는 비숫자 데이터입니다. 이러한 유형의 데이터는 종종 주제에 대한 더 깊은 이해를 얻기 위해 사용되며 사회학, 심리학 및 인류학과 같은 분야에서 일반적으로 발견됩니다. 예를 들면 개방형 설문 조사 응답, 인터뷰 녹취록 및 민족지학적 관찰이 포함됩니다. |
데이터의 유형
| 정형 데이터 | 구조화된 데이터는 테이블이나 스프레드시트와 같은 특정 형식으로 구성된 데이터입니다. 특정 스키마를 따르며 SQL과 같은 도구를 사용하여 쉽게 쿼리하고 분석할 수 있습니다. 예로는 관계형 데이터베이스, CSV 파일 및 Excel 스프레드시트가 있습니다. |
| 반정형 데이터 | 반구조화된 데이터는 특정 형식의 요소가 전부는 아니지만 일부 포함된 데이터입니다. 데이터의 형식은 유추할 수 있지만 항상 엄격한 스키마를 따르는 것은 아닙니다. 예를 들면 데이터 저장을 위한 특정 형식이 있지만 엄격한 스키마를 따르지 않을 수 있는 XML 및 JSON 파일이 있습니다. |
| 비정형 데이터 | 구조화되지 않은 데이터는 특정 형식이나 스키마가 없는 데이터입니다. 조직화되지 않고 분석하기 어려운 경우가 많습니다. 텍스트 문서, 이미지, 오디오 및 비디오 파일을 예로 들 수 있습니다. 이러한 유형의 데이터에는 자연어 처리 또는 컴퓨터 비전과 같은 분석을 위한 특수 도구 및 기술이 필요할 수 있습니다. |
데이터의 근원
| 가역 데이터 | 가역 데이터는 변형 또는 조작된 후 원래 상태로 복원 또는 복구될 수 있는 데이터를 의미합니다.이는 변환된 데이터에서 원본 데이터를 재구성할 수 있음을 의미합니다. 가역 데이터의 예로는 품질 손실 없이 원본 이미지를 압축 이미지에서 재구성할 수 있는 무손실 이미지 압축이 있습니다. |
| 비가역 데이터 | 비가역 데이터(irreversible data)는 변형이나 조작 후에 원래 상태로 되돌릴 수 없는 데이터를 말한다. 이는 원본 데이터가 손실되거나 변환된 데이터에서 재구성할 수 없음을 의미합니다. 비가역 데이터의 예로는 이미지가 압축될 때 원래 이미지 품질이 손실되고 원본 이미지로 정확하게 재구성할 수 없는 손실 이미지 압축이 있습니다. |
데이터의 기능
| 암묵지 | 암묵지은 표현하거나 전달하기 어려운 지식을 의미합니다. 그것은 종종 "노하우" 또는 "노우 댓"으로 묘사되며 개인적인 경험, 직관 및 기술을 기반으로 합니다. 암묵적 지식의 예에는 자전거 타기, 식사 요리 또는 언어 구사 능력이 포함됩니다. 암묵적 지식은 종종 데모, 견습 또는 협업을 통해 공유됩니다. |
| 형식지 | 형식지는 쉽게 표현되고 전달될 수 있는 지식을 말합니다. 그것은 종종 "알고 있는 것"으로 묘사되며 사실, 개념 및 이론을 기반으로 합니다. 명시적 지식의 예로는 과학적 법칙, 수학 공식 및 역사적 사건이 있습니다. 명시적 지식은 종종 책, 기사 또는 강의와 같은 서면 또는 구두 커뮤니케이션을 통해 공유됩니다. |
지식창조 메커니즘
| 공통화 | 이 메커니즘은 개별 암묵적 지식을 공유된 명시적 지식으로 전환하는 것을 포함합니다. 공통화는 개인이 개인적인 경험과 통찰력을 공유할 수 있도록 하는 커뮤니케이션과 협업을 통해 촉진됩니다. |
| 표출화 | 이 메커니즘은 암묵적 지식을 명료화 및 표현 과정을 통해 명시적 지식으로 전환하는 것을 포함합니다. 이 프로세스를 통해 개인은 자신의 지식을 다른 사람과 공유하고 전달할 수 있는 형태로 외부화할 수 있습니다. |
| 연결화 | 이 메커니즘은 새로운 지식을 생성하기 위해 서로 다른 명시적 지식의 통합을 포함합니다. 결합은 새로운 통찰력과 이해를 창출하기 위해 서로 다른 관점과 전문성의 결합에 의해 촉진됩니다. |
| 내면화 | 이 메커니즘은 흡수와 동화 과정을 통해 명시적 지식이 암묵적 지식으로 전환되는 것을 포함합니다. 이 과정을 통해 개인은 새로운 지식을 내면화하여 개인적인 경험과 이해의 일부로 만들 수 있습니다. |
지식의 피라미드
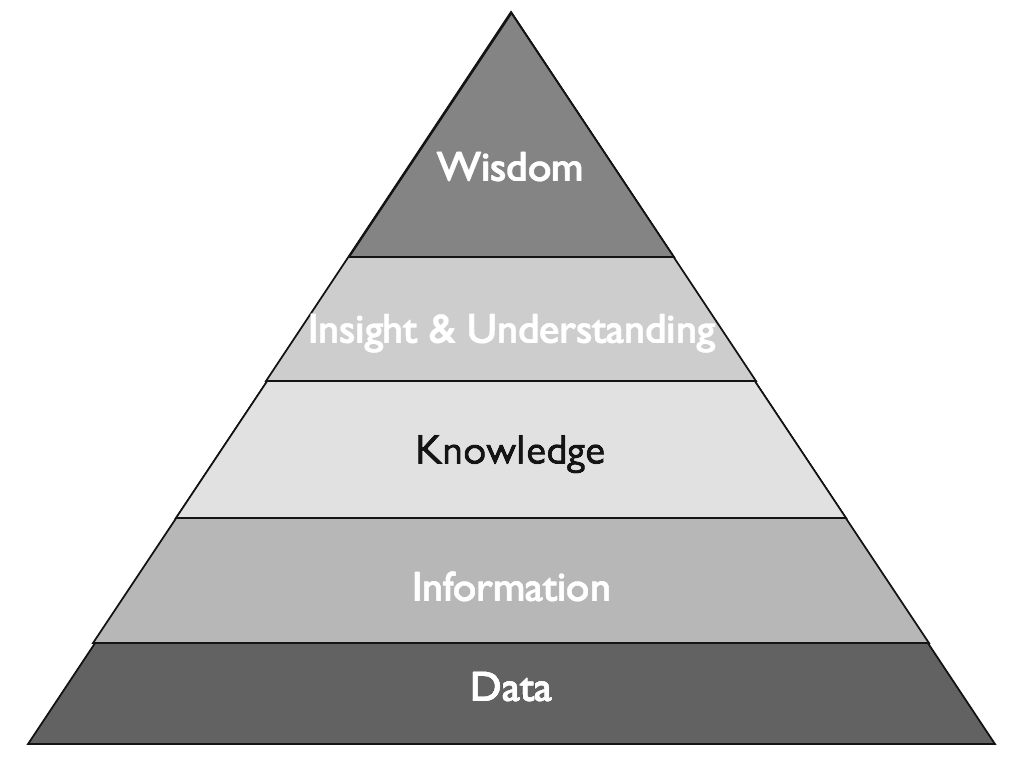
지식의 피라미드는 조직 내의 다양한 지식 수준을 설명하는 모델입니다. 그것은 Nonaka와 Takeuchi가 저서 "The Knowledge-Creating Company"에서 제안했으며 네 가지 수준으로 구성됩니다.
| 데이터 | 데이터는 아직 지식으로 변환되지 않은 가공되지 않은 원시 정보를 나타냅니다. |
| 정보 | 정보는 의미 있고 유용한 형식으로 구성되고 처리된 데이터입니다. |
| 지식 | 지식은 해석되고 이해된 정보입니다. 내재화된 데이터와 정보의 조합으로 의사결정에 활용할 수 있습니다. |
| 지혜 | 지혜는 전략적이고 전체론적인 방식으로 지식을 적용하는 능력을 나타냅니다. 큰 그림을 보고 조직에 가장 이익이 되는 결정을 내리는 능력입니다. |
지식의 피라미드는 지식의 진정한 가치는 적용하고 공유할 수 있는 능력에 있음을 강조합니다. 또한 지식의 공유와 창출을 장려하는 조직 문화 조성의 중요성을 강조합니다.
다음 글
정보의 호텔에는 미래의 데이터 전문가가 되실 분들을 위해 빅데이터분석, 데이터분석에 관한 글을 아래의 페이지에 정리해 놓았습니다.
'자격증/빅데이터분석기사' 카테고리의 글 목록
모든 분야의 정보를 담고 있는 정보의 호텔입니다.
jkcb.tistory.com
위 페이지는 빅데이터분석기사 / 데이터분석전문가 / 데이터분석준전문가 모두 유용하게 사용하실 수 있습니다.
반응형