목차
개요
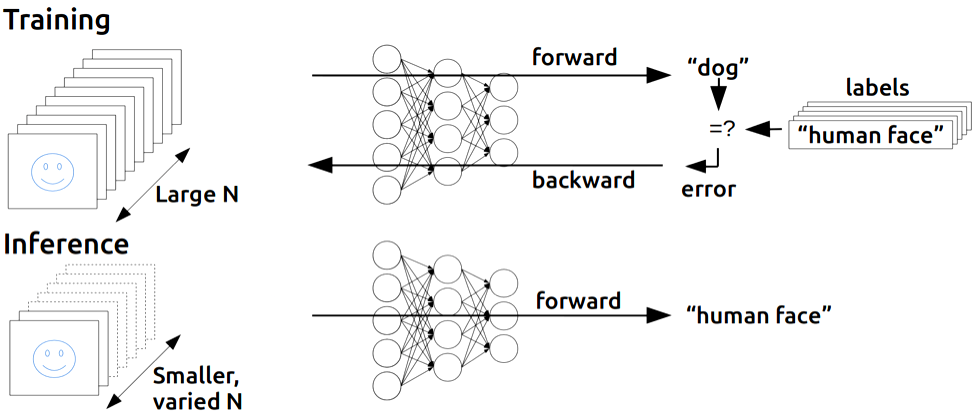
신경망의 추론 처리는 훈련된 모델을 사용하여 보이지 않는 새로운 데이터를 예측하는 프로세스입니다. 학습된 모델은 학습 프로세스 중에 학습한 패턴 및 관계를 기반으로 입력 데이터에 대한 예측 또는 추론을 수행하는 데 사용됩니다.
특징
추론 처리는 기계 학습 파이프라인의 마지막 단계이며 모델을 실제 응용 프로그램에 배포할 수 있도록 합니다. 계산 리소스가 덜 필요하고 더 빠르게 수행할 수 있다는 점에서 훈련과 다릅니다. 그러나 예측의 품질은 교육의 품질에 따라 달라집니다.
추론에는 온라인과 오프라인의 두 가지 주요 유형이 있습니다.
온라인 추론은 자율 주행 자동차 또는 음성 인식과 같이 모델이 가능한 한 빨리 예측을 수행해야 하는 실시간 애플리케이션에 사용됩니다.
오프라인 추론은 데이터 세트의 이미지 분류와 같이 대량의 데이터를 한 번에 처리해야 하는 일괄 처리 애플리케이션에 사용됩니다.
추론 과정은 정방향 통과와 역방향 통과의 두 부분으로 나눌 수 있습니다.
정방향 통과 (순전파)는 입력 데이터가 모델을 통해 전달되고 모델이 예측을 생성하는 곳입니다.
역방향 통과 (역전파)는 그래디언트가 계산되고 모델이 업데이트되는 곳입니다.
추론을 수행하려면 훈련된 모델이 필요합니다. 이 모델은 감독, 비감독 또는 강화 학습 기술을 사용하여 훈련할 수 있습니다. 사용할 기술의 선택은 문제, 데이터 및 원하는 출력에 따라 다릅니다. 모델이 훈련되면 실제 응용 프로그램에 배포하고 예측을 시작할 수 있습니다.
추론 과정을 최적화하는 것은 활발한 연구 분야입니다. 여기에는 정확도를 유지하면서 모델을 더 빠르고 효율적으로 만드는 방법을 찾는 것이 포함됩니다. 이를 달성하는 한 가지 방법은 양자화 및 가지치기 기술을 사용하는 것입니다. 양자화는 모델 매개변수의 정밀도를 낮추는 반면 가지치기는 모델에서 불필요한 매개변수를 제거합니다. 이러한 기술은 모델의 크기와 계산 시간을 크게 줄여 리소스가 제한된 장치에 배포하는 데 더 적합하도록 만들 수 있습니다.
결론적으로 신경망의 추론 처리는 훈련된 모델을 사용하여 보이지 않는 새로운 데이터를 예측하는 프로세스입니다. 기계 학습 파이프라인의 마지막 단계이며 모델을 실제 애플리케이션에 배포할 수 있습니다. 계산 리소스가 덜 필요하고 더 빠르게 수행할 수 있다는 점에서 훈련과 다릅니다. 추론 프로세스 최적화는 활발한 연구 영역이며 양자화 및 가지치기와 같은 기술은 모델의 크기와 계산 시간을 크게 줄여 리소스가 제한된 장치에 배포하는 데 더 적합하도록 만들 수 있습니다.
구현
from keras.models import load_model
import numpy as np
# load the trained model
model = load_model('trained_model.h5')
# input data for inference
x_test = np.array([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]])
# make predictions
predictions = model.predict(x_test)
# print the predictions
print(predictions)
널리 사용되는 라이브러리인 Keras를 사용하여 Python에서 신경망 추론 처리를 구현하는 방법의 예입니다.
이 예에서 모델은 학습 프로세스 중에 생성된 training_model.h5 파일에서 로드됩니다. 입력 데이터 x_test는 NumPy 배열로 제공되며 모델의 predict() 함수를 사용하여 예측합니다. 예측은 NumPy 배열로 반환되며 필요에 따라 추가로 처리할 수 있습니다.
x_test는 예측하려는 입력 데이터라는 점에 유의해야 합니다. 기능 수를 포함하여 훈련 데이터와 모양이 동일해야 하며 테스트 데이터가 동일한 방식으로 전처리되는지 확인해야 합니다. 학습 데이터로 사용합니다.
또한 특정 사용 사례 및 데이터 세트에 따라 정규화 또는 표준화와 같은 입력 데이터에 대해 다른 사전 처리 기술을 사용해야 할 수도 있습니다.
이는 단지 예일 뿐이며 특정 사용 사례 및 데이터 세트에 따라 아키텍처와 매개변수를 조정해야 할 수도 있습니다. 또한 이 예제에서는 Keras 라이브러리를 사용하지만 TensorFlow, Pytorch 등 다른 라이브러리를 사용하여 추론을 구현할 수도 있습니다.
[컴퓨터과학/딥러닝] - 파이썬의 keras를 이용해 3층 신경망을 구현해 보자 - 딥러닝
더보기
'컴퓨터과학/딥러닝' 카테고리의 글 목록
모든 분야의 정보를 담고 있는 정보의 호텔입니다. 주로 컴전기입니다.
jkcb.tistory.com